Lecture 2 Examples#1. Categorical Naïve Bayes (Play Tennis Dataset)
#2. Gaussian Naïve Bayes (Numerical Data)
#3. Principal Component Analysis (PCA)
#More On Naive Bayes
1. Categorical Naïve Bayes (Play Tennis Dataset)
The Scenario:
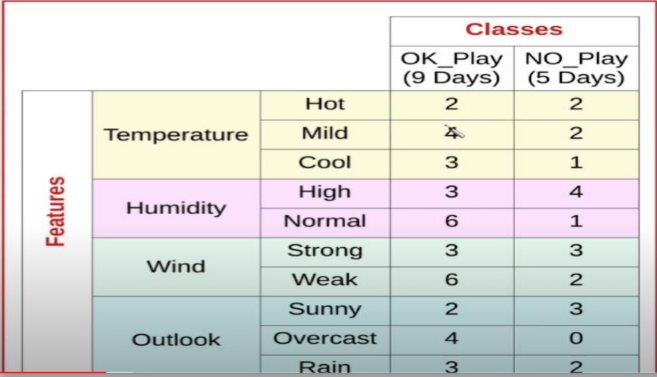
We have historical data on whether a tennis game was played (OK_Play = 9 days, NO_Play = 5 days, Total = 14 days).
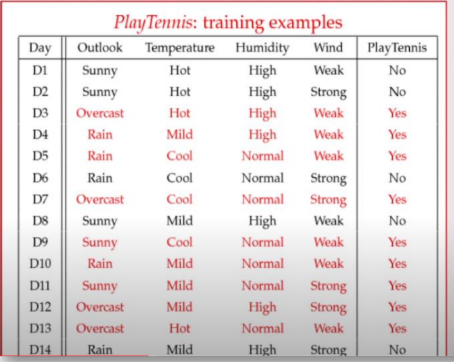
We need to classify a new, unseen day (
-
Outlook: Sunny
-
Temperature: Cool
-
Humidity: High
-
Wind: Strong
Step 1: Calculate the Probabilities for OK_Play
We multiply the likelihood of each feature occurring when the game was played by the prior probability of playing at all.
-
-
-
-
-
Prior:
Equation:
Step 2: Calculate the Probabilities for NO_Play
We do the same for when the game was not played.
-
-
-
-
-
Prior:
Equation:
Result: Since 0.0206 is greater than 0.0053, the model classifies this new day as NO_Play.
2. Gaussian Naïve Bayes (Numerical Data)
The Scenario:
Recall: the marginalization rule "total probability", is when you calculate the probability of some variable, by summing over the joint distribution of all possible values of another variable
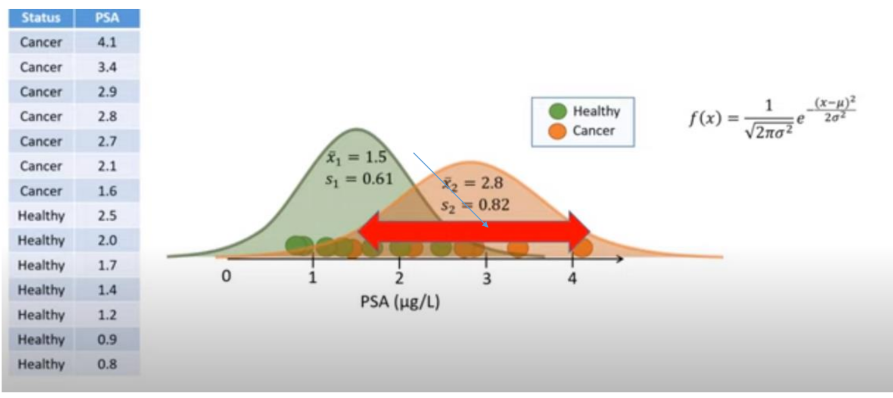
Instead of counts, we are dealing with continuous numbers (PSA level and Age) to classify a patient as Healthy or Cancer. Because we assume the features follow a normal distribution, we plug our values into the Gaussian Probability Density Function:
-
Test Patient: PSA = 2.6, Age = 70
-
Priors:
,
Step 1: Calculate Likelihoods for Healthy
Using the mean (Healthy training data:
-
PSA Likelihood:
-
Age Likelihood:
Posterior Numerator (Healthy):
Step 2: Calculate Likelihoods for Cancer
Using the mean and standard deviation from the Cancer training data:
-
PSA Likelihood:
-
Age Likelihood:
Posterior Numerator (Cancer):
Result: Since 0.013 is greater than 0.004, the model classifies the patient as having Cancer.
3. Principal Component Analysis (PCA)
The Scenario:
We want to reduce the dimensionality of a 2D dataset while preserving the most important variance.
Data Points: (2, 1), (3, 5), (4, 3), (5, 6), (6, 7), (7, 8)
Step 1: Calculate the Mean Vector (
Find the average of all
Step 2: Subtract the Mean
Center the data around the origin by subtracting the mean from every point.
-
-
...repeat for all points...
-
Step 3: Calculate the Covariance Matrix
Compute
Step 4: Find Eigenvalues and Eigenvectors
Solve the characteristic equation
- Eigenvalues:
(Principal), (We drop this small one to reduce dimensions).
Next, we solve
Step 5: Project the Data
Finally, we recast the original data points onto this new 1D principal component line by taking the dot product.
-
Projecting Point 1 (2, 1):
-
Projecting Point 2 (3, 5):
-
(This creates your new, 1-dimensional reduced dataset!)
More On Naive Bayes
Why Naive Bayes
Its main strength is requiring less training data, while its primary weakness is the "naive" assumption that all features are independent, which rarely holds true in real-world scenarios.
Pros of Naive Bayes:
- Fast and Scalable: Highly efficient in training and prediction, suitable for real-time applications and large datasets.
- Performance with Less Data: Performs well with small training sets and high-dimensional data (e.g., text categorization).
- Simplicity: Easy to implement and understand.
- Handles Multi-class: Effective for multi-class prediction tasks.
- Robust to Irrelevant Features: Not sensitive to irrelevant features in the dataset.
Cons of Naive Bayes:
- Independence Assumption: Assumes features are independent, which rarely holds true. If features are correlated, performance can degrade.
- Zero-Frequency Problem: If a categorical variable has a category in the test set that was not observed in the training set, the model will assign a zero probability.
- Not Ideal for Complex Relationships: Struggles to capture complex relationships or dependencies between features.
- Data Scarcity: Requires sufficient data for each class to accurately estimate probabilities.
Common Use Cases:
- Spam filtering
- Sentiment analysis
- Document/Article classification
- Real-time prediction systems
- Naive Assumption: We assume that all features are mutually exclusive / uncorrelated
- Recall: the marginalization rule "total probability", is when you calculate the probability of some variable, by summing over the joint distribution of all possible values of another variable
Therefore:
The "Naivety"
Calculating the exact joint probability of many interacting variables " for calculating
-
Mathematically, it changes the complex joint probability into a simple product of individual probabilities:
-
While this assumption is "naïve" because real-world variables are almost always correlated, the algorithm is famously robust. It often achieves high accuracy in classification tasks (like spam filtering) with exceptionally low computational overhead.
When making a decision between two classes (
Normalization
The Marginalization Rule (often called the Law of Total Probability) is the mathematical engine behind the denominator in Bayes' Theorem. In the context of machine learning, it is what allows us to convert raw, abstract scores into clean, readable percentages that sum up to 100% (or 1.0).
Here is Bayes' formula:
The denominator,
How to Calculate the Marginal Probability with Multiple Features
When you have multiple features (like Temperature, Humidity, Wind, or Age, PSA), calculating the exact probability of that specific combination occurring in the wild is extremely difficult.
Instead, the Marginalization Rule lets us calculate it by summing up the "numerators" of all our possible classes.
The formula for the marginal probability becomes:
The Normalization Trick (Step-by-Step)
Because the marginal probability (the denominator) is the exact same for every class you are evaluating, you do not actually need to compute it right away. You can just calculate the numerators, sum them up, and use that sum to normalize your results.
Let's use the numerical Healthy vs. Cancer example from the lecture slides to see this in action!
1. Calculate the Numerator for Class A (Healthy)
We multiply the Prior by the Likelihoods of the features (PSA = 2.6):
-
Numerator (Healthy) =
-
Numerator (Healthy) =
2. Calculate the Numerator for Class B (Cancer)
-
Numerator (Cancer) =
-
Numerator (Cancer) =
3. Apply the Marginalization Rule (Find the Denominator)
To find the total marginal probability of someone having a PSA of 2.6, we simply add the numerators together:
- Marginal Probability =
4. Normalize to get the Final Probabilities
Now, divide each class's numerator by the marginal probability to get the true, normalized posterior probabilities:
-
Final Probability (Healthy):
(or 21%) -
Final Probability (Cancer):
(rounded to 79% in the slides)
By dividing by the marginalized sum, you force the probabilities to scale proportionally so that
To use that exact marginalization rule for multiple features, we have to rely on the "Naïve" part of the Naïve Bayes algorithm: Conditional Independence.
If you have a dataset with multiple features (like PSA and Age, or Outlook, Temperature, Humidity, and Wind), trying to find the true, real-world probability of that exact combination happening all at once—
To get around this, Naïve Bayes assumes that every feature is completely independent of the others, as long as you already know the class.
Here is how that theoretical breakdown works mathematically.
1. Breaking Down the Likelihood
Because we assume the features are independent, the joint probability of all features given a specific class—
2. Expanding the Marginalization Rule
Now, we take that expanded, multiplied likelihood and plug it back into the formula you provided. To find the total marginal probability of seeing this specific combination of features across your entire dataset, you calculate this product for every single class and add them all together:
3. A Theoretical Example
Let's apply this directly to the two-feature numerical example from your lecture (PSA = 2.6 and Age = 70) to see the full equation in action.
We have two classes (Healthy and Cancer.
Part A: Calculate the inner term for Class 1 (Healthy)
Part B: Calculate the inner term for Class 2 (Cancer)
Part C: Sum them up for the Marginal Probability
Once you have that final summed number, you have successfully calculated your denominator! You then divide Healthy, and divide Cancer.
بالبلدي لو عايز زتونة الحل, لو طلب منك تعمل normalization, اجمع البسط بتاع كل الاحتمالات اللي حسبتها "ال likelihoods في ال priors بتاعت كل كلاس, سواء بقي كانت one or more than one feature"