1. Performance Evaluation
Before you can improve a model, you need to know how to measure its current performance. The lecture highlights that as model complexity increases, training error naturally decreases, but test error will eventually start to increase—creating a convex curve that represents overfitting.
Evaluating Regression Models
For regression (predicting continuous values), the slides define two primary metrics:
-
Mean Absolute Error (MAE): The average of the absolute differences between predictions and actual values. Closer to 0 is better.
-
Mean Squared Error (MSE): The average of the squared differences. (Note: The slide formula uses
, which typically denotes the mean, but in this context, it represents the predicted value comparable to ).
Evaluating Classification Models
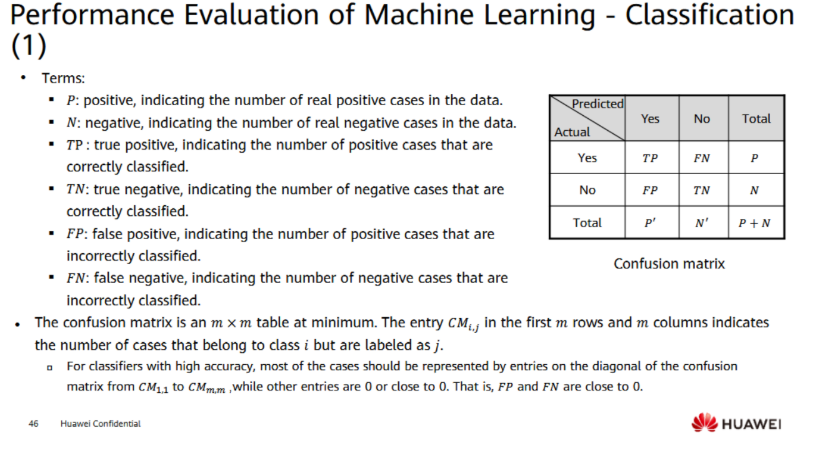
For classification, performance is broken down using a Confusion Matrix, which tracks:
-
True Positives (TP) / True Negatives (TN): Cases your model classified correctly.
-
False Positives (FP) / False Negatives (FN): Cases your model classified incorrectly.
From this matrix, we derive several critical formulas:
-
Accuracy:
(Overall correctness). -
Error Rate:
(Overall incorrectness). -
Recall (Sensitivity):
(Out of all actual positives, how many did we find?) "Completeness" . -
Precision:
(Out of all predicted positives, how many were actually positive?) "Soundness" . -
F1 Score:
(The harmonic mean of precision and recall, useful when classes are imbalanced).
2. Hyperparameter Tuning
As discussed in previous lectures, hyperparameters are external configurations set manually by the user (like the learning rate
The standard search process is:
-
Divide data into train, validation, and test sets.
-
Optimize internal parameters on the training set.
-
Search for the best hyperparameters using the validation set.
-
Alternate until finalized, then do a final assessment on the test set.
Search Methods:
-
Grid Search: Tests every single possible combination on a manually specified grid. It is highly exhaustive but extremely expensive and time-consuming, making it unfeasible for deep neural networks.
-
Random Search: Samples random combinations from a broad range, eventually narrowing down the search area based on where the best results are found. This is much more efficient for large search spaces.
3. Optimizer Types
Optimizers are the specific algorithms used to update the weights of your model during training. They aim to accelerate convergence, prevent getting stuck in local minimums, and simplify learning rate adjustments.
1. Standard Gradient Descent Updates weights by taking a step in the negative direction of the gradient.
2. Momentum Optimizer Standard gradient descent can get stuck or oscillate. Momentum fixes this by adding a fraction of the previous update to the current update. It acts like a ball rolling down a hill, gaining inertia to push through flat spots or small bumps.
زي اي حاجة بتتدحرج علي تل, كل ما تفضل ماشي في اتجاه ثابت, تكتسب سرعة اكبر في نفس الاتجاه دهز
3. AdaGrad (Adaptive Gradient) Instead of using one global learning rate (
Problem: Because
4. RMSProp (Root Mean Square Propagation) RMSProp fixes AdaGrad's "shrinking to zero" problem by introducing an attenuation coefficient (decay factor
5. Adam (Adaptive Moment Estimation) Adam is essentially the combination of Momentum and RMSProp, and it is the default choice for most modern deep learning.
-
It calculates the moving average of the gradient (
, the First Moment, like Momentum). -
It calculates the moving average of the squared gradient (
, the Second Moment, like RMSProp). -
It applies a bias correction (
and ) to prevent these values from being biased toward zero at the start of training. -
The default parameters are highly stable:
, , , and .
تلخيصة القوانين كلها تحت اهي سيبك من القوانين اللي فوق
Here is a complete comparison of the five optimization algorithms, followed by a step-by-step numerical walkthrough for two epochs.
1. Optimizer Comparison & Equations
Each optimizer attempts to solve the core problem of standard gradient descent: finding the minimum error efficiently without getting stuck in flat regions or overshooting the target. Let
1. Stochastic Gradient Descent (SGD)
-
Concept: The baseline method. It calculates the gradient of the loss and takes a step of size
in the opposite direction. It is simple but can be slow and easily gets stuck in local minima. -
Equation:
2. Momentum
-
Concept: Adds an "inertia" term (
). Instead of just relying on the current gradient, it remembers the direction of the previous updates (controlled by ). This helps push the optimizer through flat surfaces and dampens oscillations. -
Equations:
3. AdaGrad (Adaptive Gradient)
-
Concept: Abandons the idea of a single global learning rate. It divides the learning rate by the square root of
(the sum of all past squared gradients). Features that update frequently get smaller learning rates, while rare features get larger ones. -
Equations:
4. RMSProp (Root Mean Square Propagation)
-
Concept: Fixes AdaGrad's fatal flaw (the learning rate shrinking to zero). Instead of accumulating all past squared gradients, it uses an exponentially decaying moving average (
), controlled by . This keeps the learning rate adaptable but prevents it from dying out. -
Equations:
5. Adam (Adaptive Moment Estimation)
-
Concept: The industry standard. It combines the "inertia" of Momentum (First Moment,
) with the "adaptive learning rate" of RMSProp (Second Moment, ). It also includes bias correction ( and ) to ensure the initial steps aren't artificially small. -
Equations:
2. Numerical Example (2 Epochs)
Let's trace these optimizers mathematically using a static gradient to see how they behave differently. For simplicity in the hand calculations, we will ignore the tiny
Initial Conditions:
-
Starting Weight (
): 1.0 -
Constant Gradient (
): 0.5 -
Learning Rate (
): 0.1 -
Momentum/RMSProp Factor (
): 0.9 -
Adam Factors (
, ): 0.9, 0.999 -
All accumulators (
): 0
Epoch 1 (
-
SGD
-
Momentum
-
-
AdaGrad
-
-
RMSProp
-
-
Adam
-
Epoch 2 (
-
SGD
-
Momentum
-
-
(Notice how the step size is increasing due to momentum)
-
-
AdaGrad
-
-
(Notice how the effective learning rate shrank)
-
-
RMSProp
-
-
Adam
-
more on optimizers here