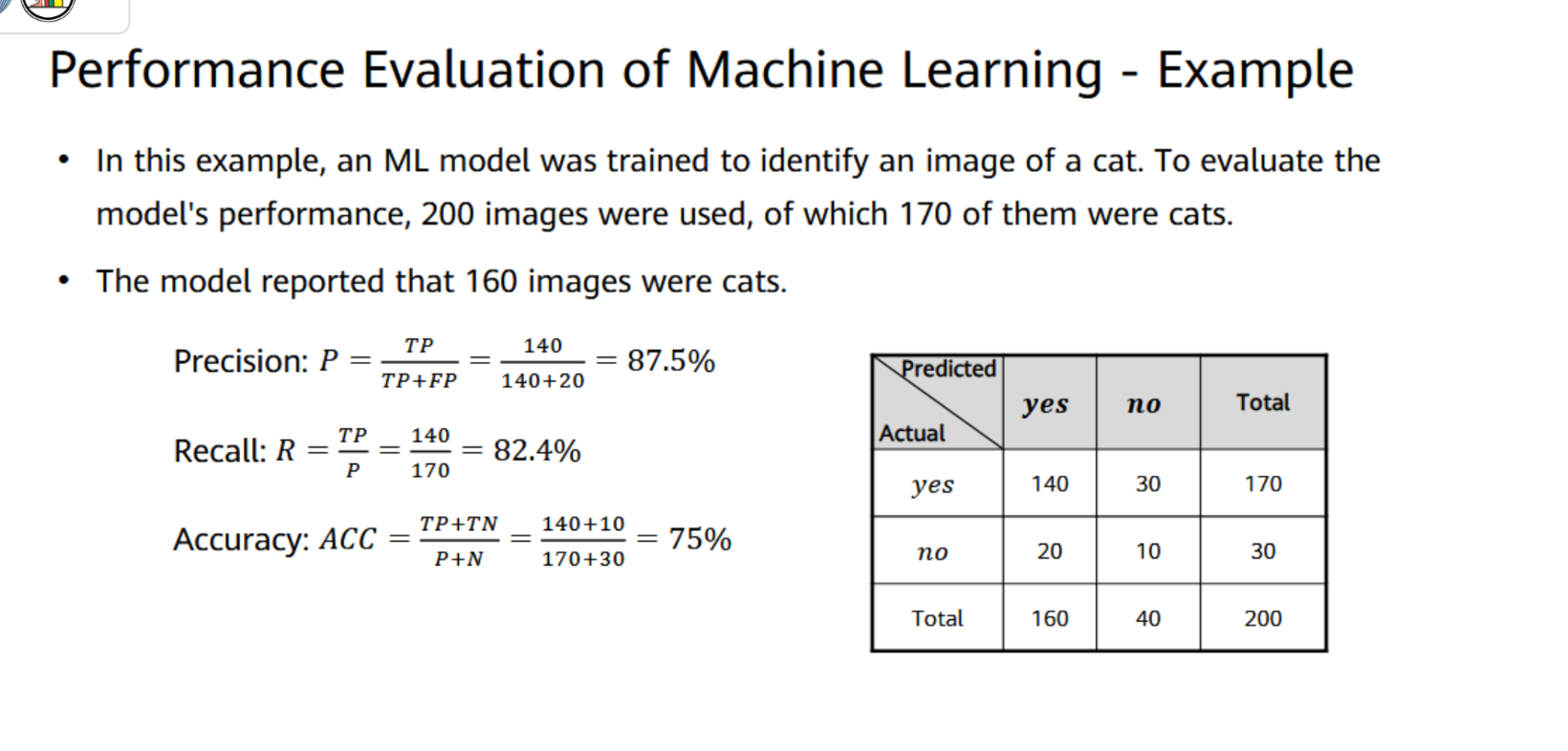
Example On Confusion Matrix
More On Optimizers
Introduction to Optimizers in Machine Learning
-
Optimizers are critical algorithms in the training process of machine learning models.
-
They determine how model weights are updated during backpropagation, applicable to both neural networks and simpler models like linear regression.
-
Stochastic Gradient Descent (SGD) is the simplest and most well-known optimizer.
-
The Adam optimizer (Adaptive Moments), introduced in 2015, has revolutionized the ML community, cited over 176,000 times.
-
In 2018, an improved variant called AMSGrad was introduced to correct a minor issue in Adam's proof.
-
Adam and its variants are typically the optimizers of choice for modern ML models, including large language models (LLMs).
-
This video aims to explain the math behind these optimizers, their practical applications, and recent research insights.
Overview of the Machine Learning Training Process
- Training starts by passing input data through the model to produce predictions.
- A loss function quantifies the difference between predicted outputs and ground truth labels.
- Example: A 3D loss function plotted against two parameters,
and , shows the loss as the height at any coordinate. - The goal is to find parameter values that minimize loss—reaching the "star" or global minimum on the loss surface.
- Real-world models can have tens, hundreds, or even billions of parameters, making visualization of the loss surface impossible beyond 3D.
Gradient and Gradient Descent Fundamentals
- The gradient of the loss function with respect to model parameters points in the direction of steepest ascent.
- To minimize loss, we move parameters in the direction of the negative gradient, which points downhill.
- The gradient vector's length changes depending on the steepness of the loss surface; normalized here for illustration.
- Repeated gradient descent steps progressively reduce loss by nudging parameters downhill.
Parameter Updates via Learning Rate
- Parameter updates are computed as:
where is the learning rate and is the gradient. - Smaller gradients near minima result in smaller update steps.
- Repeating this update millions or billions of times ideally finds the minimum loss.
Role of Optimizers in Gradient Descent
- SGD simply scales the gradient by the learning rate and subtracts it from parameters.
- SGD can be slow, especially in complex loss landscapes, requiring many steps and sometimes taking inefficient detours.
- More advanced optimizers like SGD with momentum, RMSProp, and Adam introduce enhancements that accelerate convergence and reduce the number of steps.
- Efficient optimizers reduce computational time and environmental impact by lowering electricity consumption during training, while accelerating innovation.
Momentum: Speeding Up SGD
- Momentum borrows the physics concept where a rolling ball accelerates downhill instead of moving at constant velocity.
- If consecutive gradients point in the same direction, momentum allows larger parameter updates.
- This is achieved by accumulating past gradients weighted by a hyperparameter
(commonly 0.9), forming a velocity term : - Momentum helps traverse flat regions faster and reduces the number of iterations to reach minima, often outperforming vanilla SGD.
- However, momentum can cause overshooting and oscillations (spiraling behavior) near minima.
Mathematical Details of SGD with Momentum
- Momentum updates involve an exponentially weighted average of gradients, giving recent gradients more influence than older ones.
- This weighting is due to powers of
decreasing the contribution of older gradients geometrically. - Typically, only the learning rate is tuned while keeping
fixed for simplicity and effectiveness.
Nesterov Accelerated Gradient (NAG)
- NAG refines momentum by first taking a step in the previous velocity direction, then correcting with the current gradient.
- This anticipatory step leads to more controlled and faster convergence than classical momentum.
- Empirical results show NAG can reach minima faster than momentum alone, but performance may vary by problem.
- NAG, momentum, and vanilla SGD are all available under the SGD class in PyTorch and TensorFlow.
Challenges with Momentum and SGD on Ill-Conditioned Loss Surfaces
- In loss surfaces where gradients differ significantly across parameters (e.g.,
), SGD and momentum can be inefficient. - These optimizers tend to optimize parameters sequentially rather than simultaneously, causing slow convergence.
- Such conditions arise in sparse datasets where some features are mostly zero but occasionally informative.
RMSProp: Adaptive Learning Rates for Each Parameter
- RMSProp adapts the learning rate individually for each parameter based on its gradient history.
- It computes a moving average of squared gradients (second moment estimate) to normalize updates:
is a small constant to prevent division by zero, typically . - Parameters with consistently large gradients get smaller effective learning rates, balancing updates across all parameters.
- This leads to more direct optimization paths in uneven loss landscapes.
Relation to AdaGrad and AdaDelta
- AdaGrad also adapts learning rates per parameter by accumulating squared gradients but does not decay older gradients, causing learning rates to shrink excessively over time.
- RMSProp resolves this by using an exponentially weighted moving average to limit this decay.
- AdaDelta similarly limits gradient history but is distinct and less commonly discussed here.
Adam: Combining Momentum and Adaptive Learning Rates
- Adam integrates both momentum (first moment estimate) and RMSProp-style adaptive learning rates (second moment estimate).
- First moment (
) approximates the mean of gradients; second moment ( ) approximates the uncentered variance (mean squared gradients). - Update steps:
- Bias-corrected estimates:
- Bias correction compensates for initialization of
and at zero, which would otherwise dampen early updates. - Default hyperparameters are
, , and .
Adam's Performance on Complex Loss Functions
- Adam excels in complex loss landscapes with multiple minima, capable of escaping local minima and finding the global minimum faster than SGD, SGD with momentum, and RMSProp.
- Potential downside: If the learning rate is too high, Adam may overshoot the global optimum and settle in a local minimum.
- Proper tuning of hyperparameters is essential to maximize Adam's benefits.
Benchmark Comparisons of Optimizers on Real Datasets
| Dataset / Model | Optimizer | Performance (Training Loss / Accuracy) | Notes |
|---|---|---|---|
| Fashion MNIST (10 epochs) | Adam, RMSProp, SGD, SGD + Momentum | Adam and RMSProp outperform SGD variants significantly. | Adam slightly better than RMSProp. |
| CIFAR-10 (ResNet18) | Adam, RMSProp, others | Adam leads in training loss reduction and test accuracy. | Consistent with meta-analysis studies. |
| Various CNNs (Meta-analysis) | Adam, RMSProp, NAdam, SGD variants | Adam or AdamX optimizers perform best; SGD variants lag behind. | AdamX recommended for CIFAR-10 models. |
| Wildlife Image Classification | Adam vs. RMSProp | Adam shows higher mean accuracy in most models. | Confirms Adam’s effectiveness in vision tasks. |
- Meta-analyses confirm Adam’s consistent superior performance across different architectures and datasets.
- RMSProp also performs well, particularly in reinforcement learning contexts.
Reinforcement Learning (RL) Experiment Findings
- Tested optimizers on policy gradient training in the Pong environment.
- Results showed variability: sometimes RMSProp outperformed Adam, sometimes vice versa.
- Hypothesis: RL data distribution shifts during training as the agent explores, causing sample dependence.
- Momentum-based optimizers may underperform in RL because past gradient directions become less reliable due to changing data distributions.
- Both Adam and RMSProp are widely used in RL; choice depends on specific problem characteristics.
- Conclusion: No single optimizer is universally best; experimentation is crucial.
Memory Considerations in Optimizer Selection
- Adam requires maintaining two additional vectors per parameter (first and second moments), tripling memory usage compared to vanilla SGD.
- Memory efficiency is critical in training large models (e.g., multi-billion parameter LLMs) on multiple GPUs.
- Minimizing communication and memory overhead across GPUs is addressed by libraries such as Microsoft’s DeepSpeed using Zero Redundancy Optimizers (ZeRO).
- ZeRO splits optimizer states across GPUs to reduce memory usage and speed up training by ~300%.
- Understanding optimizer memory requirements is essential for practical large-scale ML training.
Closing Remarks
- Optimizers dramatically impact training speed, convergence quality, and resource usage in machine learning.
- Adam, combining momentum and adaptive learning rates, generally provides the best performance across many tasks but requires careful tuning.
- Alternative optimizers like RMSProp and NAG have specific scenarios where they outperform or complement Adam.
- Practical ML demands understanding optimizer mechanics, trade-offs, and memory costs to make informed choices.
- Further exploration into advanced optimizers and distributed training frameworks is encouraged.
Key Concepts Summary
| Term | Definition/Role |
|---|---|
| Optimizer | Algorithm that updates model parameters to minimize loss during training. |
| SGD (Stochastic Gradient Descent) | Basic optimizer updating parameters via scaled gradients; simple but can be slow. |
| Momentum | Technique to accelerate SGD by accumulating past gradients, speeding convergence. |
| Nesterov Accelerated Gradient (NAG) | Momentum variant with anticipatory step for more controlled updates. |
| RMSProp | Uses running average of squared gradients to adapt learning rates per parameter, improving on AdaGrad. |
| Adam (Adaptive Moments) | Combines momentum and RMSProp, using bias-corrected first and second moment estimates. |
| Bias Correction | Adjustment to counteract initial zero bias in moment estimates, crucial in early training. |
| Learning Rate ( |
Step size multiplier controlling how far parameters move each update. |
| Hyperparameters ( |
Control decay rates of moment estimates in Adam and RMSProp. |
| ZeRO Optimizer | Distributed optimizer state partitioning technique to reduce memory footprint in multi-GPU training. |
Summary Table: Optimizer Characteristics
| Optimizer | Key Feature | Pros | Cons | Typical Use Cases |
|---|---|---|---|---|
| SGD | Basic gradient descent | Simple, low memory | Slow convergence, sensitive to learning rate | Small/simple models, baseline |
| SGD + Momentum | Accumulates past gradients | Faster convergence, handles flat regions | Possible overshoot, oscillations | General deep learning tasks |
| NAG | Momentum with lookahead | More controlled updates than momentum | Slightly more complex, not always better | Tasks needing faster convergence |
| RMSProp | Adaptive learning rates | Handles different gradient scales well | Can get stuck in local minima | Sparse data, RL, uneven loss landscapes |
| Adam | Momentum + adaptive rates + bias correction | Fast, robust, escapes local minima | High memory use, sensitive to tuning | Most modern DL and RL tasks |
Recommendations and Final Notes
- Always tune learning rates carefully for any optimizer.
- Use Adam as the default starting optimizer for most deep learning tasks.
- Consider RMSProp or NAG for specialized scenarios such as reinforcement learning or highly sparse data.
- Monitor optimizer memory usage when scaling to large models; tools like DeepSpeed ZeRO can mitigate overhead.
- Experimentation is essential, as no single optimizer universally outperforms others in every context.
This Explanation is mainly based on this Video Who's Adam and What's He Optimizing? | Deep Dive into Optimizers for Machine Learning! - YouTube