Q1
There appears to be a typo in the diagram. The bottom arrow originating from
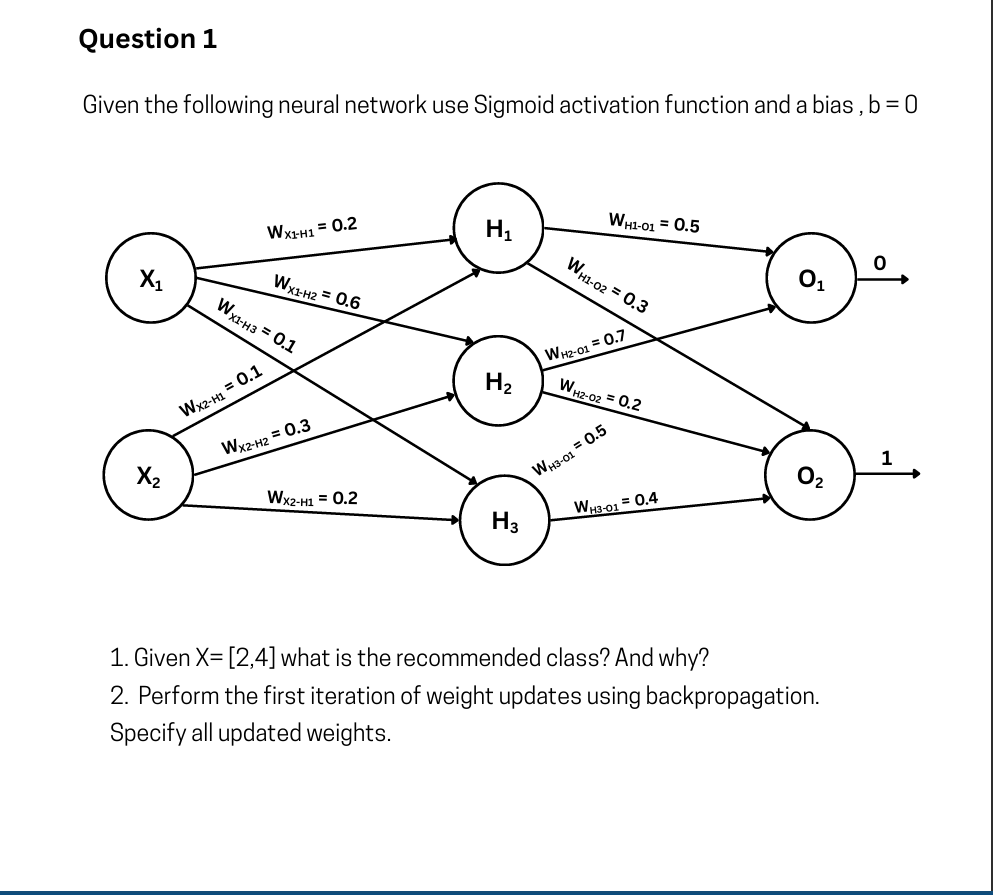
1. Given X = [2,4] what is the recommended class? And why?
To find the recommended class, we need to perform a forward pass through the network using the given inputs (
Step A: Calculate Hidden Layer Activations (
First, we find the weighted sum (
-
For
: -
For
: -
For
:
Step B: Calculate Output Layer Activations (
Now, we use the hidden layer activations to compute the final outputs.
-
For
(Class 0): -
For
(Class 1):
Conclusion:
The recommended class is Class 0.
Why: The calculated activation for the
2. Perform the first iteration of weight updates using backpropagation. Specify all updated weights.
To perform a mathematical weight update via backpropagation, two critical pieces of information are missing from the problem prompt:
-
The True Target Labels (
): We need to know what the network should have predicted for the input to calculate the loss/error margin. -
The Learning Rate (
): We need the hyperparameter that determines the step size of the weight updates.
How to proceed:
If you can provide the target labels and the learning rate expected by your professor or assignment, I can complete the backpropagation calculations for you.
As a reference, once you have those values, the update for a weight connecting the hidden layer to the output layer (assuming Mean Squared Error loss) would follow this formula:

Setup & Values from the Forward Pass
-
Learning Rate (
): 0.1 -
Target (
): The previous recommended class was Class 0. The opposite is Class 1. Therefore, the target values for the output nodes are: (for ) and (for ). -
Inputs:
, -
Cached Forward Pass Activations (rounded to 4 decimal places for accuracy):
-
, , -
,
-
(Note: We will use the standard Mean Squared Error loss derivative for the Sigmoid activation function:
Step 1: Calculate the Output Layer Errors (
-
For
(Target ): -
For
(Target ):
Step 2: Update the Output Layer Weights
The weight update formula is:
Step 3: Calculate the Hidden Layer Errors (
To calculate the error for the hidden nodes, we backpropagate the output errors using the original weights before they were updated.
Formula:
-
For
: -
For
: -
For
:
Step 4: Update the Hidden Layer Weights
The weight update formula is:
-
-
-
-
-
-
(Using the assumed correction from earlier that the bottom-most arrow is )
Q2: Derive the weight equation of Minimum sum squared errors.

Q3
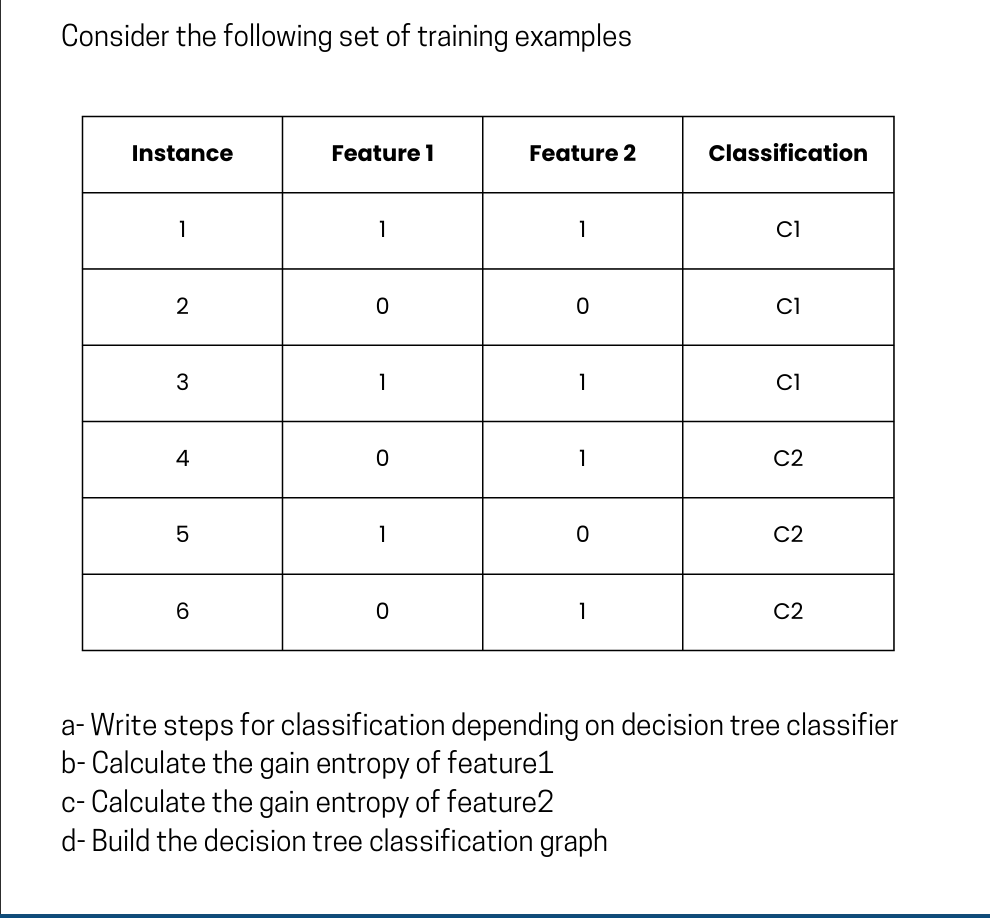
a- Steps for classification depending on decision tree classifier
To build a decision tree (specifically using the ID3 algorithm which relies on Information Gain), you follow these standard steps:
-
Calculate the Entropy of the target dataset: Determine the uncertainty of the entire dataset based on the class labels.
-
Calculate the Entropy for each feature: For every feature, calculate the entropy of its individual branches (values) and then compute the weighted average entropy for that feature.
-
Calculate Information Gain: Subtract the weighted entropy of each feature from the target dataset's total entropy.
-
Select the Root Node: Choose the feature with the highest Information Gain to split the dataset.
-
Repeat for Child Nodes: Recursively apply steps 1-4 to the subsets of data created by the split. Stop when a subset is pure (contains only one class) or when no more features are left to split.
Initial Calculation: Parent Entropy
Before calculating the gain for specific features, we must find the total entropy of the dataset,
-
Total instances (
) = 6 -
Class C1 count = 3
-
Class C2 count = 3
b- Calculate the gain entropy of Feature 1
First, we analyze the splits if we use Feature 1:
-
If Feature 1 = 0: Instances {2, 4, 6} (Total = 3)
-
C1 count = 1 (Instance 2)
-
C2 count = 2 (Instances 4, 6)
-
-
-
If Feature 1 = 1: Instances {1, 3, 5} (Total = 3)
-
C1 count = 2 (Instances 1, 3)
-
C2 count = 1 (Instance 5)
-
-
Now, calculate the weighted entropy for Feature 1,
Finally, calculate Information Gain:
c- Calculate the gain entropy of Feature 2
Next, we analyze the splits if we use Feature 2:
-
If Feature 2 = 0: Instances {2, 5} (Total = 2)
-
C1 count = 1 (Instance 2)
-
C2 count = 1 (Instance 5)
-
-
-
If Feature 2 = 1: Instances {1, 3, 4, 6} (Total = 4)
-
C1 count = 2 (Instances 1, 3)
-
C2 count = 2 (Instances 4, 6)
-
-
Now, calculate the weighted entropy for Feature 2,
Finally, calculate Information Gain:
d- Build the decision tree classification graph
Since Feature 1 has the higher Information Gain (
Because neither subset is perfectly pure after the first split, we apply Feature 2 to the resulting branches to complete the classification:
-
If
, looking at the dataset, results purely in C1, and results purely in C2. -
If
, looking at the dataset, results purely in C2, and results purely in C1.
Here is the resulting decision tree structure:
Plaintext
[Feature 1]
/ \
(0) (1)
/ \
[Feature 2] [Feature 2]
/ \ / \
(0) (1) (0) (1)
/ \ / \
[C1] [C2] [C2] [C1]
Q4

1. What is the output provided by a convolution layer?
We have a
The output size will be:
The kernel is essentially an identity matrix:
This means that for every
-
Row 1 Calculations:
-
Window 1 (cols 1-2):
-
Window 2 (cols 2-3):
-
Window 3 (cols 3-4):
-
Window 4 (cols 4-5):
-
Following this sliding window process across the entire matrix gives us the following output feature map:
2. The output of the convolution layer goes through The ReLU layer, what will the output of this layer be?
The Rectified Linear Unit (ReLU) activation function sets all negative values to zero while keeping positive values unchanged:
Applying this to our
3. The output of the ReLU layer goes through a maxpooling layer with size
Max pooling extracts the maximum value from the window. The problem does not explicitly state the stride for the pooling layer. When dealing with a
(Note: If the stride were 3, only one
Using a
-
Top-Left Window: The max value in the upper
quadrant is . -
Top-Right Window: The max value in the upper right
quadrant is . -
Bottom-Left Window: The max value in the lower left
quadrant is . -
Bottom-Right Window: The max value in the lower right
quadrant is .
Final Output Matrix:
Q5
1. Difference between Bagging and Boosting
Both are ensemble learning techniques used to improve model performance, but they operate differently:
| Feature | Bagging (Bootstrap Aggregating) | Boosting |
|---|---|---|
| Execution | Parallel: Models are trained independently at the same time. | Sequential: Models are trained one after another. |
| Focus | Aims to reduce variance (prevents overfitting). | Aims to reduce bias (improves underfitting) and variance. |
| Data Sampling | Random subsets of data are drawn with replacement for each model. | All data is used, but weights of previously misclassified data points are increased for the next model. |
| Base Learners | Usually complex, high-variance models (e.g., deep Decision Trees). | Usually simple, high-bias weak learners (e.g., shallow Decision Trees/stumps). |
| Aggregation | Equal majority vote (classification) or simple average (regression). | Weighted vote/average based on each model's accuracy. |
| Examples | Random Forest | AdaBoost, Gradient Boosting, XGBoost |
2. Assumptions of Linear Regression
For a linear regression model to be valid and reliable, it relies on four main assumptions (often remembered by the acronym LINE), plus one regarding features:
-
Linearity: The relationship between the independent variables (X) and the mean of the dependent variable (Y) is strictly linear.
-
Independence: The observations (and thus the residuals) are independent of one another. There is no hidden autocorrelation.
-
Normality of Residuals: The error terms (residuals) of the model are normally distributed.
-
Equal Variance (Homoscedasticity): The variance of the residuals remains constant across all values of the independent variables (the spread of errors doesn't fan out or funnel in).
-
No Multicollinearity: The independent variables should not be highly correlated with each other.
3. Importance of Data Normalization
Data normalization (scaling numerical features to a standard range, like 0 to 1, or standardizing them to have a mean of 0 and a variance of 1) is critical for several reasons:
-
Equal Feature Weighting: It prevents features with naturally larger numerical ranges (e.g., salary in the thousands) from dominating features with smaller ranges (e.g., age in decades) when using distance-based algorithms like KNN or K-Means.
-
Faster Convergence: In optimization algorithms like Gradient Descent (used in Neural Networks and Logistic Regression), normalized data creates a smoother, more symmetrical error landscape, allowing the model to converge to the minimum much faster.
-
Numerical Stability: It prevents issues like vanishing or exploding gradients and floating-point overflow during computation in deep learning.
4. Convolutional Layer Calculations
Here are the calculations based on your provided parameters:
-
Input (
): -
Filters (
): 128 -
Filter Size (
): (Depth is 3, matching the input) -
Stride (
): 3 -
Padding (
): 2
a. Calculate the width and height of the output feature maps:
We use the standard dimension formula:
Because the input is square (
- Output Width and Height:
(The full output volume is ).
b. Determine the total number of units (neurons) in the output:
The total number of units is the volume of the output feature map (Width
c. Compute the total number of learnable parameters:
Each filter has weights corresponding to its volume, plus exactly one bias term. We then multiply by the total number of filters.