Q1
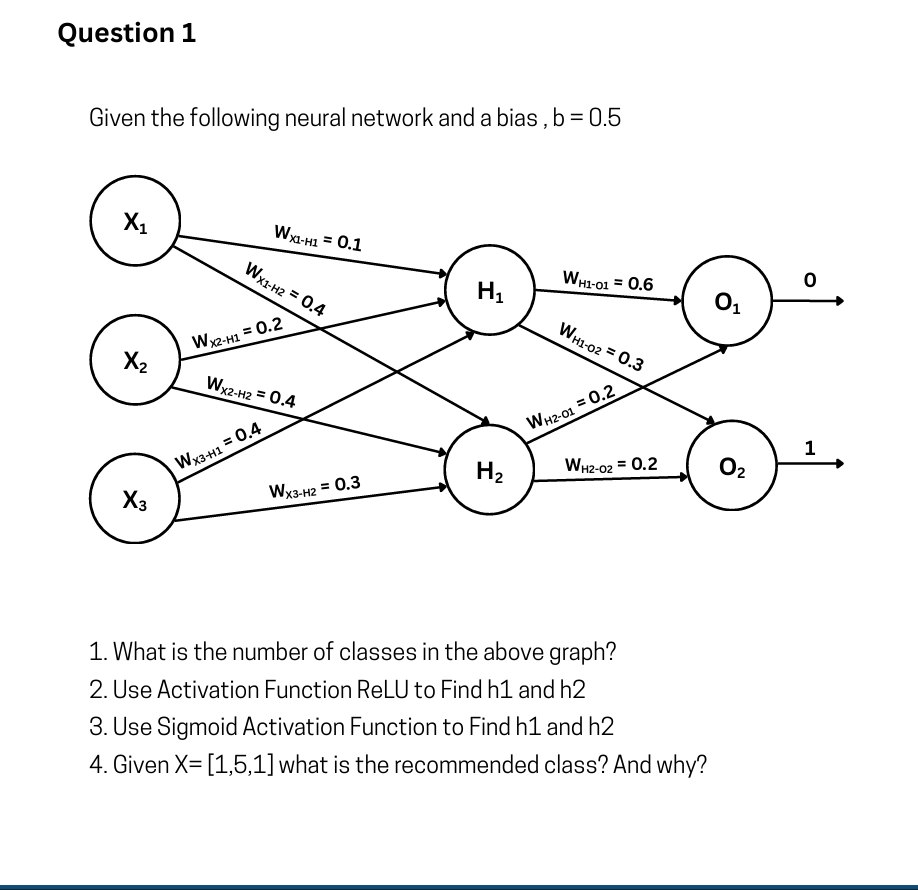
To solve questions 2 and 3, we need to use the input values provided in question 4:
First, let's calculate the pre-activation values (the weighted sum plus bias) for the hidden nodes
1. What is the number of classes in the above graph?
There are 2 classes.
The output layer consists of two nodes (
2. Use Activation Function ReLU to Find
The ReLU (Rectified Linear Unit) activation function outputs the input directly if it is positive, otherwise, it outputs zero:
3. Use Sigmoid Activation Function to Find
The Sigmoid activation function is defined as:
4. Given
To find the recommended class, we need to compute the final values for the output nodes
Let's calculate the pre-activation outputs for
Conclusion:
The recommended class is Class 0.
Why: Because the calculated value for the
Q2
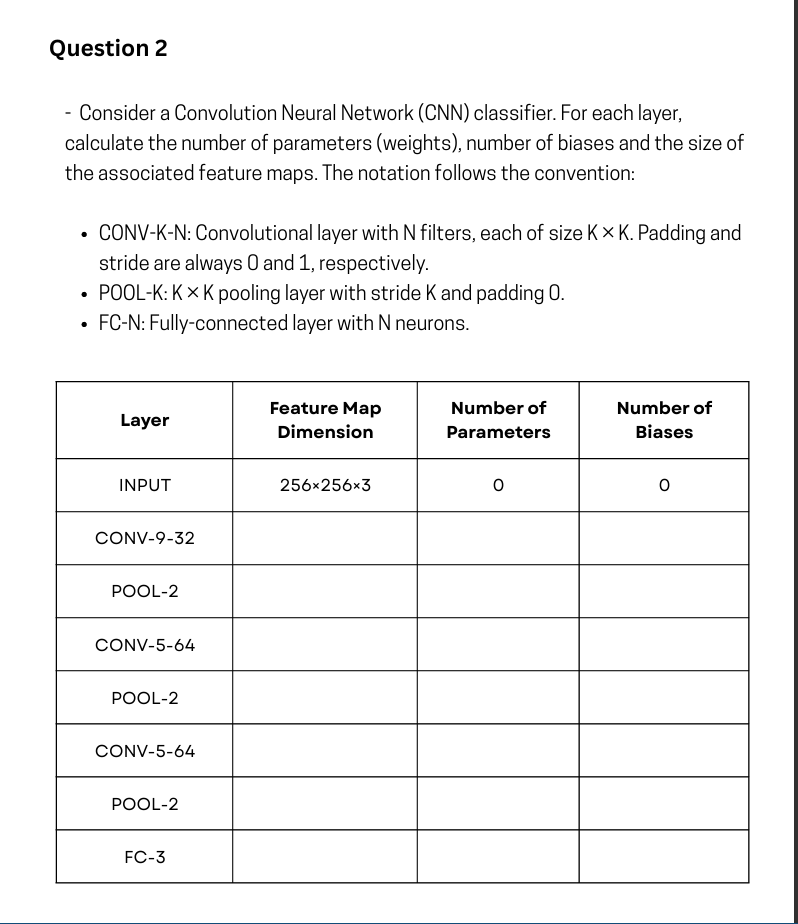
Completed Table
| Layer | Feature Map Dimension | Number of Parameters (Weights) | Number of Biases |
|---|---|---|---|
| INPUT | 0 | 0 | |
| CONV-9-32 | 32 | ||
| POOL-2 | 0 | 0 | |
| CONV-5-64 | 64 | ||
| POOL-2 | 0 | 0 | |
| CONV-5-64 | 64 | ||
| POOL-2 | 0 | 0 | |
| FC-3 | 3 | 3 |
Formulas Used
The problem explicitly asks to separate the "Number of Parameters (Weights)" from the "Number of Biases".
1. Feature Map Dimension:
-
Convolution Layer:
- Given
and , this simplifies to:
- Given
-
Pooling Layer:
- Given stride
, this simplifies to:
- Given stride
2. Number of Parameters (Weights):
-
Convolution Layer:
(where is input channels/depth, is number of filters ). -
Pooling Layer:
(Pooling has no learnable weights). -
Fully-Connected Layer:
(Requires flattening the previous layer's output).
3. Number of Biases:
-
Convolution Layer: 1 bias per filter =
-
Fully-Connected Layer: 1 bias per neuron =
Step-by-Step Breakdown
1. CONV-9-32
-
Dimension:
. The depth becomes 32 (number of filters). -
Weights:
-
Biases:
2. POOL-2
-
Dimension:
. Depth remains unchanged. -
Weights & Biases:
(Pooling layers only perform aggregation, e.g., max or average).
3. CONV-5-64
-
Dimension:
. Depth becomes 64. -
Weights:
-
Biases:
4. POOL-2
-
Dimension:
. Depth remains 64. -
Weights & Biases:
5. CONV-5-64
-
Dimension:
. Depth remains 64. -
Weights:
-
Biases:
6. POOL-2
-
Dimension:
. Depth remains 64. -
Weights & Biases:
7. FC-3
-
Note: Before passing data to a Fully-Connected layer, the 3D output of the previous layer must be flattened into a 1D vector. * Flattened Size:
features. -
Dimension: The output is simply a 1D array representing the 3 classes.
-
Weights:
-
Biases:
Q3

Proof

Q4: MCQ
Question 1
In K-Nearest Neighbors (KNN), what is the effect of choosing a very small value for 'K' (e.g., K=1)?
-
Correct Answer: A. The model becomes more prone to overfitting the training data.
-
Explanation: When K=1, the model strictly assigns the class of the single closest data point. This makes the decision boundary highly complex and jagged because it reacts to every single piece of noise or outlier in the training data. This high variance and low bias scenario is the classic definition of overfitting.
Question 2
What is a potential consequence of setting the learning rate (η) too high in gradient descent?
-
Correct Answer: B. The gradient descent algorithm will oscillate around the minimum without converging, overshooting the optimal values.
-
Explanation: The learning rate determines the size of the steps the algorithm takes down the error gradient. If it is set too high, the steps are so large that the algorithm will "step over" the lowest point of the valley (the minimum). It will bounce back and forth across the slopes and can even diverge, causing the error to increase rather than decrease.
Question 3
Suppose you are implementing a KNN model with 10 features, but you suspect that some of the features are more important than others for prediction. What can you do to account for this in the distance calculation?
-
Correct Answer: A. Assign weights to each feature, multiplying each feature distance by its weight.
-
Explanation: Standard distance metrics (like Euclidean distance) treat every feature equally. If you know certain features are more predictive, you can modify the distance formula to include a weight multiplier for those specific features. This forces the algorithm to penalize differences in the "important" features more heavily than differences in the less important ones.
Question 4
What is the main advantage of Mini-Batch Gradient Descent compared to both Stochastic Gradient Descent (SGD) and Batch Gradient Descent (BGD)?
-
Correct Answer: D. Mini-Batch GD combines the efficiency of SGD with the stability of BGD, offering faster convergence and reduced variance.
-
Explanation: Batch GD calculates the gradient using the entire dataset, which is stable but very slow and memory-intensive. SGD updates weights using only one data point at a time, which is fast but highly noisy and erratic. Mini-batch strikes a balance: by using a small chunk (batch) of data, it utilizes matrix operations for computational efficiency while smoothing out the erratic noise of SGD, leading to a much more stable convergence.
Question 5
Which one is NOT from the advantages of KNN?
-
Correct Answer: C. High accuracy for imbalanced data
-
Explanation: KNN struggles heavily with imbalanced datasets. Because it relies on a simple majority vote from the nearest neighbors, a data point that belongs to a rare minority class will frequently be surrounded by data points from the overwhelming majority class. As a result, the minority class is often outvoted, leading to poor accuracy for the minority class. (KNN is simple, requires no active training phase, and is highly flexible to non-linear data).