The lecture continues the exploration of optimization and introduces how agents handle uncertainty and structural constraints. It marks a significant evolution in how we represent the "world" the AI is operating in.
1. Local Search in Continuous Spaces
Previous algorithms assumed a discrete environment (like moving on a grid). However, most real-world environments are continuous, meaning the branching factor is infinite.
When you are architecting base estimators for modular machine learning libraries from scratch, this is exactly the type of optimization you are dealing with—finding the minimum of a continuous loss function.
-
The Approach: Instead of checking discrete neighbors, we use calculus. The lecture highlights the Newton-Raphson method, a general technique for finding the roots of functions (
). -
The Formula: It iteratively updates the estimate using the derivative:
(Note: In ML context, this is conceptually similar to how gradient descent uses the derivative to step toward the minimum cost).
2. Searching with Nondeterministic Actions
In the real world, actions don't always have guaranteed outcomes. If an environment is partially observable or nondeterministic, a single sequence of actions will inevitably fail when something unexpected happens.
-
Contingency Plans: Instead of returning a linear path, the search algorithm must return a strategy (or contingency plan) containing nested
if-then-elsestatements. -
AND-OR Search Trees: To model this, the search tree is split into two types of nodes:
-
OR Nodes: These represent the agent's choices (e.g., the vacuum decides to move Left, Right, or Suck).
-
AND Nodes: These represent the environment's nondeterministic response (e.g., if the agent sucks, the dirt might be removed, AND it might accidentally leave dirt behind).
-
A solution requires finding a successful path for every possible outcome generated by an AND node.
-
To truly grasp AND-OR trees, we have to abandon the idea of finding a "path" and instead think about finding a "strategy."
In deterministic environments (like the 8-puzzle or the Missionaries and Cannibals problem), the agent is in complete control. If it decides to move a tile, the tile moves. The solution is just a linear list of steps: [Up, Left, Down, Right].
But what happens when the agent doesn't have total control?
The Structure of an AND-OR Tree
When an environment is nondeterministic (unpredictable) or adversarial (involving an opponent), a linear plan will instantly break the moment the environment does something unexpected. To survive, the agent must build a tree of contingency plans.
This tree alternates between two types of nodes:
1. OR Nodes (The Agent's Choices)
-
Visualized as: Squares or upward-pointing triangles.
-
The Logic: At this node, the agent looks at its available actions and says, "I can do action A, OR action B, OR action C."
-
Winning Condition: The agent only needs one of these branches to successfully lead to the goal.
2. AND Nodes (The Environment's/Opponent's Responses)
-
Visualized as: Circles or downward-pointing triangles.
-
The Logic: Once the agent commits to an action, the environment dictates the outcome. The agent must say, "If I do action A, the environment might result in outcome X, AND it might result in outcome Y."
-
Winning Condition: Because the agent cannot choose the outcome, a valid strategy must have a guaranteed path to the goal for outcome X AND outcome Y. If even one outcome leads to a dead end, the entire parent action is unsafe.
A Concrete Example
When structuring the logic for a chess engine—especially when calculating complex combinations that involve forced moves, castling, or pawn promotion—a standard search path completely fails. You cannot plan a linear 5-move sequence to achieve checkmate because the opponent is actively trying to ruin it.
In this context, the search tree is perfectly modeled by AND-OR logic (often formalized as Minimax in adversarial games):
-
Your turn (OR Node): You look at the board. You can move your Knight OR your Bishop. You only need to find one good move.
-
Opponent's turn (AND Node): If you move your Knight, the opponent might take it with a Pawn, AND they might ignore it and check your King. To guarantee that your Knight move is mathematically sound, you must have a winning follow-up prepared for the Pawn capture AND the King check AND every other legal move they could possibly make.
What does a "Solution" look like?
In a standard search, the solution is a line from start to finish.
In an AND-OR search, the solution is a subtree containing nested if-then-else rules.
If we mapped out a plan, it would look like this:
-
[OR] I will play Knight to f7.
-
[AND] * If the environment (opponent) plays Rook takes Knight
[OR] I will play Queen to e8 (Checkmate). - If the environment (opponent) plays King moves to g8
[OR] I will play Knight to h6 (Checkmate).
- If the environment (opponent) plays King moves to g8
Because you have an answer for every branch of the AND node, the strategy is completely watertight.
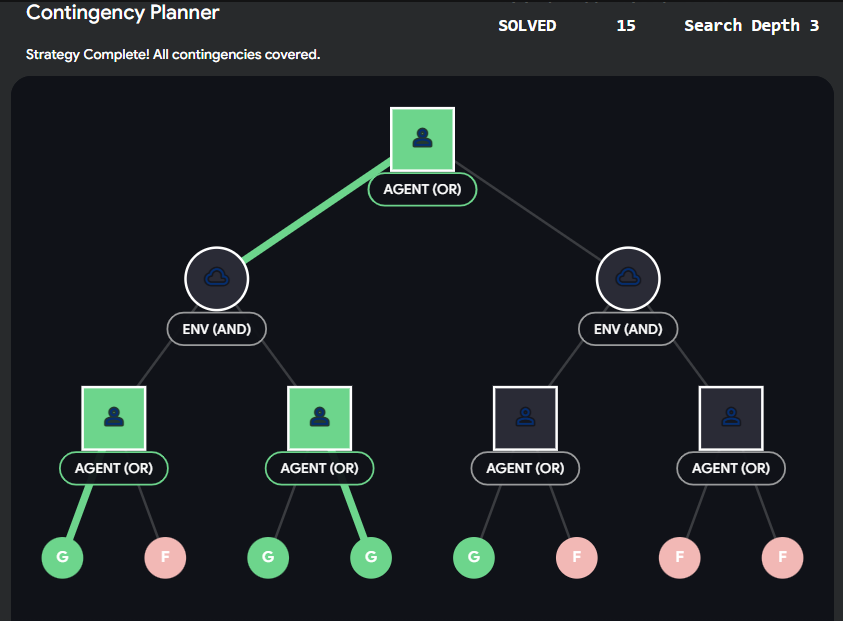
Interactive AND-OR Strategy Builder
The hardest part of implementing this logic is understanding how the "Goal" propagates back up the tree.
-
An OR node is marked as "Solved" if just one of its children is solved.
-
An AND node is marked as "Solved" ONLY if all of its children are solved.
Try to find the guaranteed winning strategy in the abstract widget below.
To find the solution for the erratic vacuum cleaner, we have to trace the execution of the AND-OR-GRAPH-SEARCH algorithm provided in your lecture over the tree structure shown on Slide 15.
Because the vacuum is erratic, an action like Suck in State 1 is nondeterministic—it might clean the dirt and transition to State 7, or it might fail and transition to State 5. Therefore, the algorithm cannot return a simple sequence of actions; it must return a contingency plan consisting of if-then-else rules.
Here is the step-by-step application of "finding the solution," following the successful path (highlighted in red on your slide).
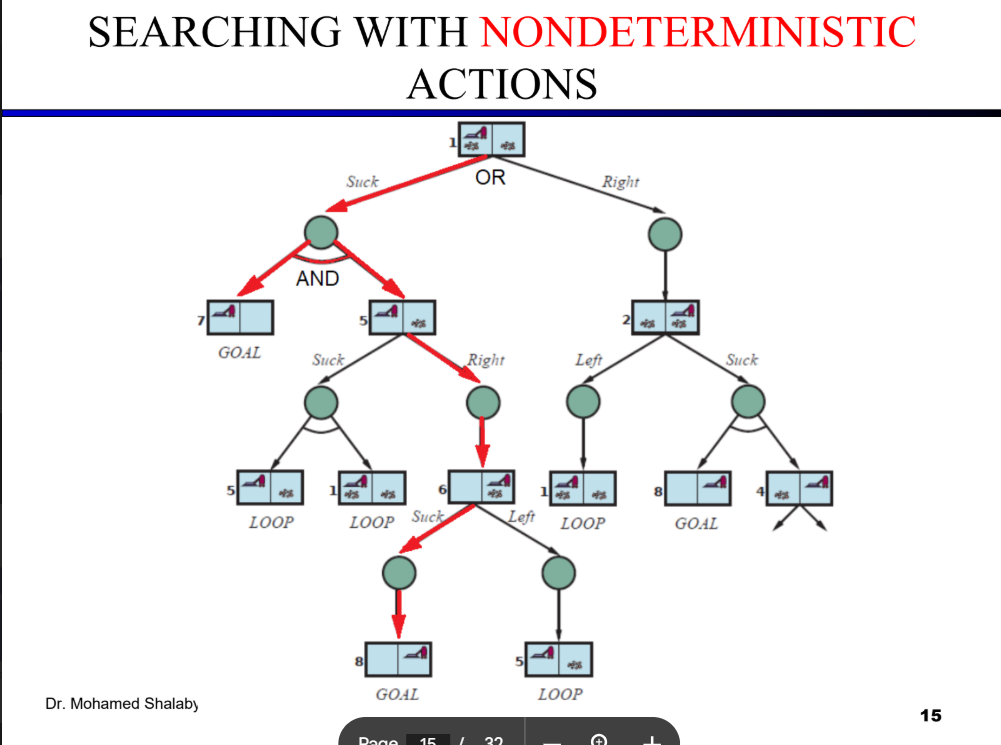
The Step-by-Step Search Trace
1. The Root Choice (OR Node: State 1) The agent begins at State 1 and must choose an action (Right or Suck). The algorithm explores Suck.
2. The Environment's Response (AND Node) Because the environment is nondeterministic, the Suck action branches into an AND node with two possible outcomes: State 7 and State 5. To successfully validate the initial Suck command, the AND-SEARCH function dictates that the agent must find a winning path for both outcomes.
3. Solving Outcome A: State 7 The algorithm evaluates State 7 and recognizes it as a GOAL. According to the algorithm, if the state passes the goal test, it returns an empty plan ([]). This branch of the AND node is successfully resolved.
4. Solving Outcome B: State 5 (OR Node)
State 5 is not a goal, so the agent must choose a new action to continue the plan.
-
The Failed Branch: If the agent chooses
Suck, the environment might transition back to State 1 or remain in State 5. TheOR-SEARCHfunction checks its path history, detects aLOOP(a state already visited), and immediately returnsfailureto prevent an infinite cycle. -
The Successful Branch: The agent chooses
Right. The environment dictates this leads to State 6.
5. Continuing from State 6 (OR Node)
State 6 is not a goal. The agent must choose again.
-
The Failed Branch: If the agent chooses
Left, it transitions to State 5. The algorithm detects this as aLOOPand returnsfailure. -
The Successful Branch: The agent chooses
Suck. The environment transitions to State 8.
6. State 8 (Goal) The algorithm evaluates State 8 and recognizes it as a GOAL. The algorithm returns an empty plan ([]).
Constructing the Final Strategy
Because a successful path was found for every possible outcome of the initial Suck command, the root node is considered solved. As the recursive functions return back up the tree, the AND-SEARCH algorithm stitches the successful branches together using if-then-else logic.
The final solution returned by the algorithm is a robust contingency strategy:
Action 1:
[Suck]Condition:
[if State=7 then [] else if State=5 then [Right, Suck]]
3. Constraint Satisfaction Problems (CSPs)
This is a massive paradigm shift in state representation. Previously, algorithms treated states as Atomic—a "black box" with no internal structure where you just ask "Is this the goal?".
CSPs use a Factored representation. A state is now a set of variables, and the problem is solved by assigning values to these variables without breaking the rules.
-
The Components of a CSP:
-
: A set of variables . -
: A set of domains containing the allowed values for each variable. -
: A set of constraints specifying which combinations of values are legal.
-
-
Why use CSPs? By understanding the internal structure of a state, the algorithm can use general-purpose logic to eliminate massive portions of the search space all at once, rather than blindly checking every combination.
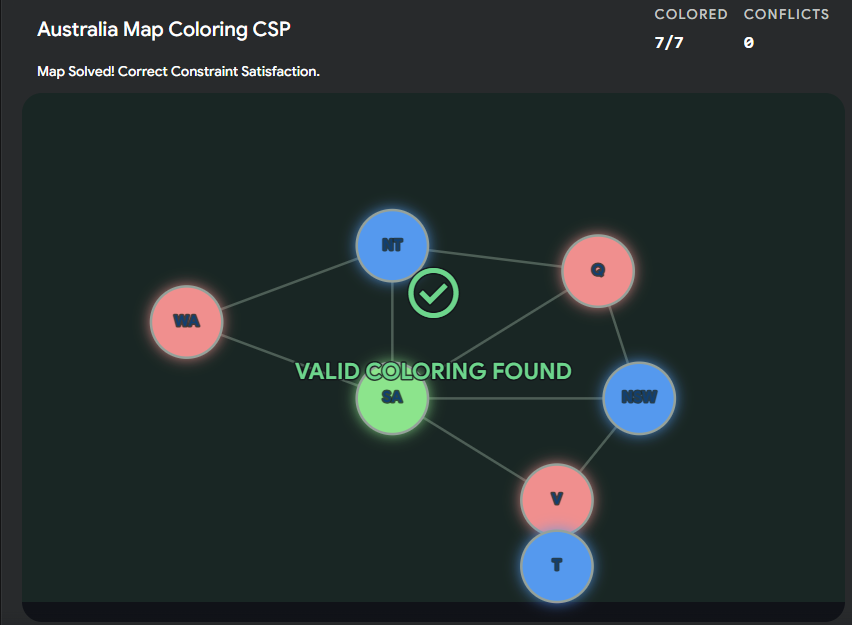
Interactive Concept: CSP Map Coloring
The lecture uses the map of Australia as a classic CSP example.
-
Variables (
): The territories (WA, NT, SA, Q, NSW, V, T). -
Domain (
): Three colors (e.g., Red, Green, Blue). -
Constraint (
): No two adjacent territories can share the same color.