
(a) Conditional Probability Table
In a Noisy-OR model, the probability that the effect
Let
First, we extract the failure probabilities
- Find
:
. Therefore, . - Find
:
.
Using the Noisy-OR formula:. - Find
:
.
Using the formula:.
Now, we calculate the missing values in the table:
- Row 2 (
): - Row 4 (
): - Row 5 (
): - Row 6 (
):
Completed Table:
| 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 1/6 |
| 0 | 1 | 0 | 1/3 |
| 0 | 0 | 1 | 7/10 |
| 1 | 1 | 0 | 4/9 |
| 1 | 0 | 1 | 3/4 |
| 0 | 1 | 1 | 4/5 |
| 1 | 1 | 1 | 5/6 |
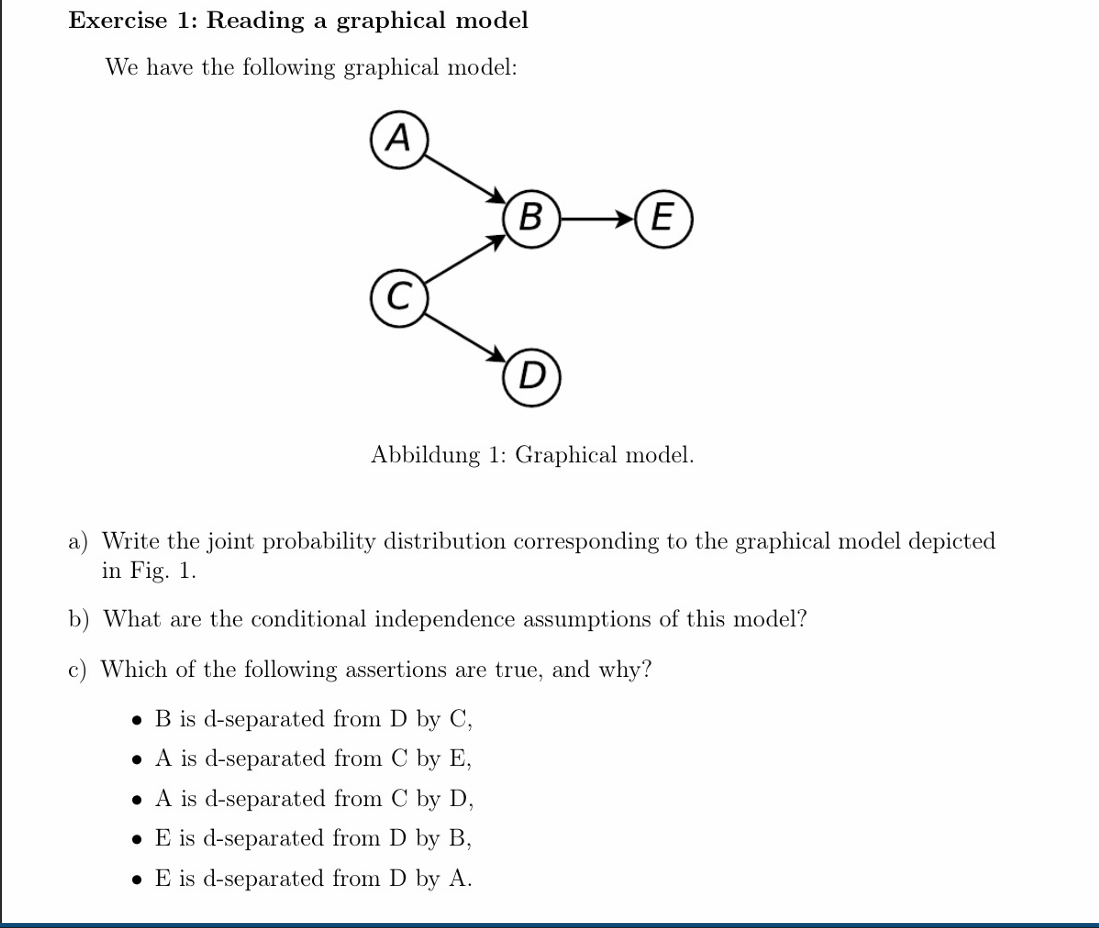
a) Joint Probability Distribution
The joint probability distribution for a Bayesian network is the product of the conditional probability distributions of each node given its parents.
Looking at the graph, we can identify the parents for each node:
-
: No parents -
: No parents -
: Parents are and -
: Parent is -
: Parent is
Therefore, the joint probability distribution is:
b) Conditional Independence Assumptions
The fundamental assumption of a Bayesian network (the Local Markov Property) is that each node is conditionally independent of its non-descendants given its parents. Applying this rule to each node in the model gives us the following conditional independence assumptions:
-
Node A: Has no parents. Its non-descendants are
and . - Assumption:
(A is independent of C and D)
- Assumption:
-
Node C: Has no parents. Its non-descendant is
. - Assumption:
(C is independent of A)
- Assumption:
-
Node B: Parents are
. Its non-descendant is . - Assumption:
- Assumption:
-
Node D: Parent is
. Its non-descendants are . - Assumption:
- Assumption:
-
Node E: Parent is
. Its non-descendants are . - Assumption:
- Assumption:
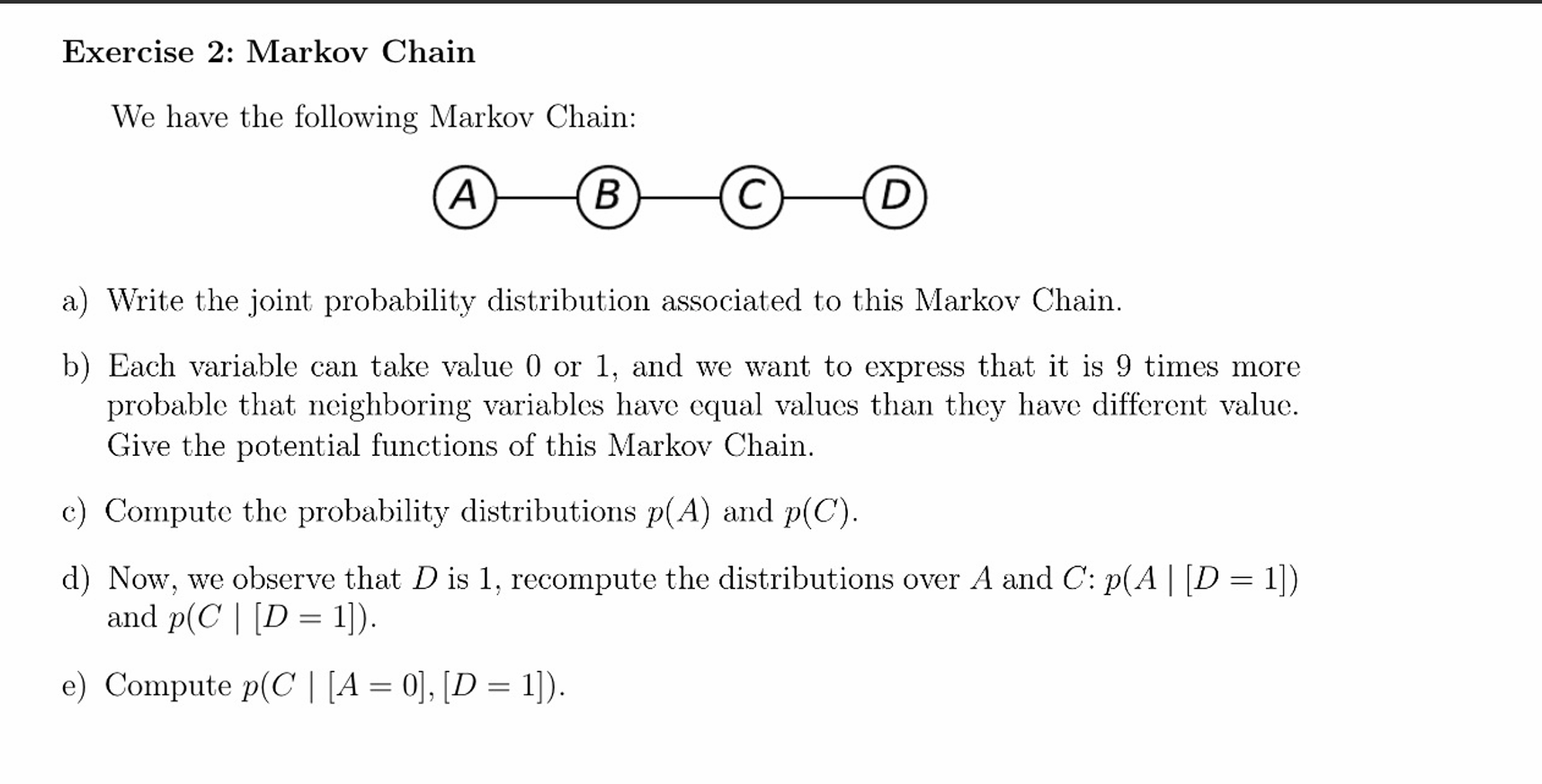
a) Joint Probability Distribution
In an undirected model, the joint probability distribution is factored into potential functions (often denoted as
The joint probability distribution is:
Where
b) Potential Functions
The problem states that each variable takes a value of 0 or 1, and it is 9 times more probable for neighboring variables to have equal values than different values.
Since the rule applies identically across the entire chain, we can use the same potential function for all pairs:
We can define the potential function
-
if -
if
Expressed as a table (or matrix) where the rows represent
| Y=0 | Y=1 | |
|---|---|---|
| 9 | 1 | |
| 1 | 9 |