Meaning of "pushing summations inward"
The concept of "pushing summations inward" is the mathematical heart of why Variable Elimination is so much more efficient than the brute-force approach. At its core, it is an algorithmic optimization built entirely on the distributive property of multiplication over addition—the same fundamental rule that states
Instead of distributing multiplication over a massive set of additions (which creates a combinatorial explosion), Variable Elimination factors out the terms that don't depend on the variable you are currently summing over.
Here is exactly what that means, mapping the algebra directly to the numerical example from slides 3 through 9.
1. The Brute Force Approach: "Un-pushed" Summations
In the lecture's example of the network
To do this using the full joint distribution (Method 2, Slides 6 & 7), you define the marginal probability as the sum over all possible states of
If we expand
The Algorithmic Flaw: Because the summations are entirely on the outside, the algorithm is forced to compute the inner product
2. Pushing the Summations Inward
To optimize this, we look at the variables involved in each factor.
Notice the innermost sum over
The factor
We have successfully "pushed" the sum over
3. Mapping to the Numerical Example (Method 1)
That newly restructured equation dictates the exact, step-by-step Variable Elimination algorithm shown in Slides 4 and 5. By isolating subproblems, we prevent the table size from exploding.
Step 1: The Inner Bracket (Eliminating A - Slide 4)
The innermost operation is now isolated:
-
Product: We multiply the factors that actually care about
: . This only requires calculating combinations of and (max size ). -
Sum-out: We marginalize
out of that product to create a new, intermediate factor: .
Step 2: The Outer Bracket (Eliminating B - Slide 5)
We substitute our new factor
-
Product: We multiply the remaining factors that involve
: . Again, this table only tracks and (max size ). -
Sum-out: We marginalize
out to get our final target: . This yields .
The Efficiency Payoff
By pushing the summations inward, we isolate the mathematical operations into decoupled blocks.
As shown in Slide 8, instead of generating a monolithic
Why does the order in which we eliminate variables matter so much
The order in which you eliminate variables is the single most important factor in Variable Elimination because it directly dictates the computational cost (both time and memory) of the algorithm.
To put it simply: a good elimination order makes a problem trivially easy to solve, while a bad order can make the exact same problem mathematically impossible for a computer to process.
Here is a breakdown of why this happens:
1. It Dictates the Size of Intermediate Tables
Every time you eliminate a variable, you have to multiply all the factors that involve that variable together.
-
If you eliminate a variable that is connected to only one or two other variables, you create a small intermediate table (e.g., a table with
rows). -
If you eliminate a variable that is connected to many other variables—like a central "hub" in your network—you are forced to multiply all those related factors together at once. This creates a massive intermediate table.
2. The "Fill-in Edge" Effect and Induced Width
When you eliminate a variable from the graph, you conceptually "marry" all of its neighbors, creating what are called fill-in edges. All of those neighbors are merged into a single clique.
The complexity of the Variable Elimination algorithm is completely determined by the maximum factor size generated during the entire process. In graph theory, the size of the largest clique created during elimination is related to the graph's induced width. The time and memory required scale exponentially with this width.
3. Avoiding the Exponential Wall
Imagine a network shaped like a star, where one central node
-
A Bad Order: If you choose to eliminate the central node
first, you must multiply all 20 outer nodes together into one gigantic factor. You suddenly have to calculate and store a table with rows (over 1 million entries). -
A Good Order: If you eliminate the 20 outer nodes one by one first, you only ever deal with small, 2-variable factors (tables of 4 rows). The math is done in fractions of a second.
This is why, in the lecture's student performance example, eliminating the unobserved leaf node
Purpose of Moralization
The primary purpose of moralization is to convert a directed Bayesian Network into an undirected graph so that the Variable Elimination (VE) algorithm can process it correctly.
Here is why this step is mathematically necessary:
-
A Unified Framework: Variable Elimination is designed to treat both Bayesian Networks (directed) and Markov Networks (undirected) using the exact same algebraic framework, which relies on "factors".
-
The Problem with Parents: In a Bayesian Network, a node's Conditional Probability Table (CPT), denoted as
, relies on the node itself ( ) and all of its parents ( ). -
The Clique Requirement: In the language of undirected graphs, a factor can only exist if all the variables within its scope are directly connected to one another, forming a "clique".
How Moralization Solves This:
If two parent nodes share a child, they are part of the same CPT, but they might not be directly connected to each other in the original directed graph.
Moralization fixes this by "marrying the parents". You draw a new undirected edge between any parents that share a child, and then you drop the directional arrows from all other edges.
For example, in the lecture's student performance network, Intelligence (
"Student Performance" example
1. Network Setup and Moralization (Slides 12–14)
The example uses a 5-node Bayesian Network representing a student's academic path. The variables are Difficulty (
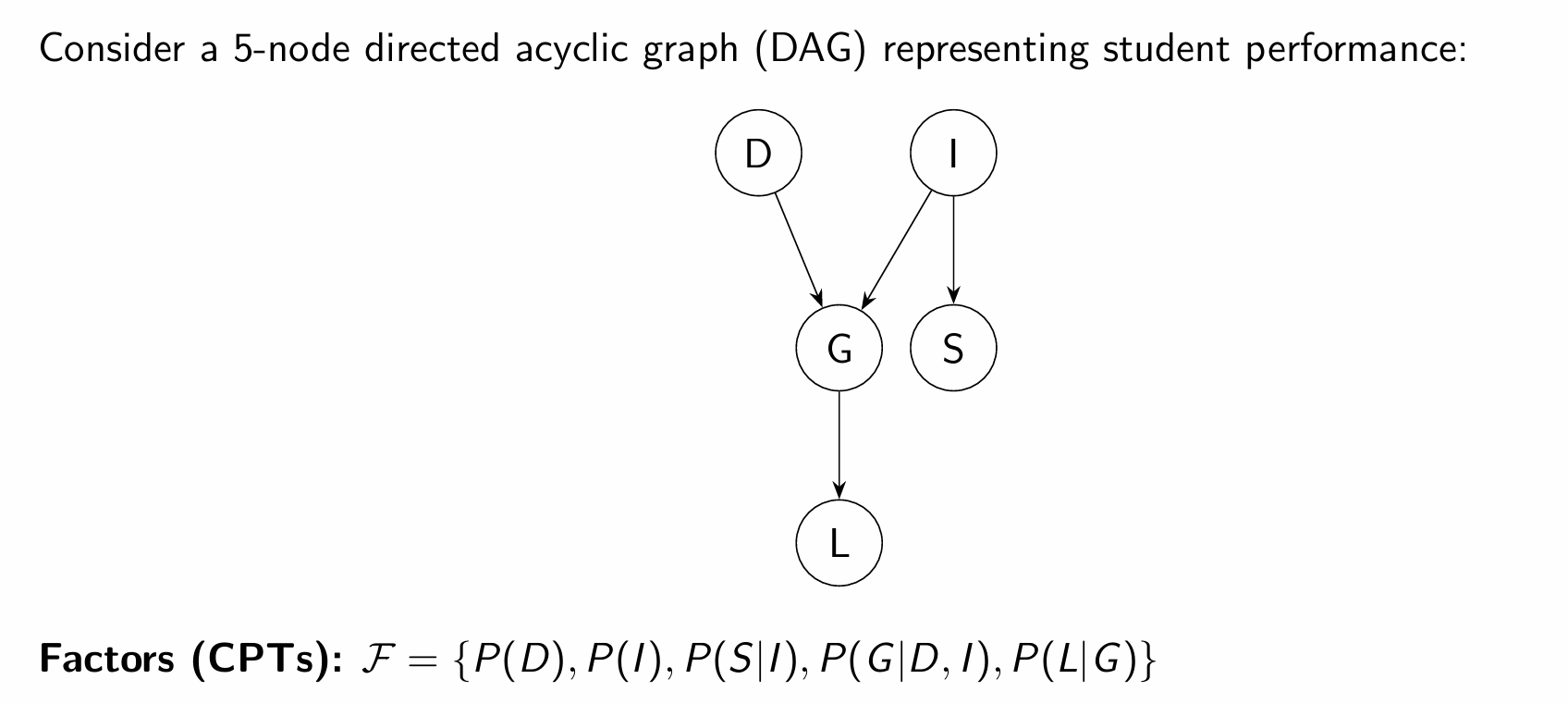
To prepare for Variable Elimination, the directed graph is "moralized" into an undirected graph. Because
2. The Query and Strategy (Slide 15)
The goal is to calculate the marginal probability of the student getting a good recommendation letter, or
The chosen elimination order is
3. Step-by-Step Execution (Slides 16–19)
Step 1: Eliminating S (The Barren Node)
-
Action: Isolate the factor involving
, which is , and sum it out to create a new factor . -
Math:
. -
For
: . -
For
: .
-
-
Insight: Because
is a "leaf node" (it has no children) and is unobserved (we don't know the SAT score), summing it out results in a factor of 1s. This proves the "Barren Node Rule"— has no mathematical impact on the final calculation.
Step 2: Eliminating I
-
Action: Multiply the factors involving
: , , and our new factor of 1s from the previous step, then sum out . This creates a new 2-variable factor . -
Math:
. -
Calculating for
: We use the prior probabilities for ( , meaning ). . . -
Calculating for
: . .
-
We only explicitly calculated the values for
Here is the full breakdown of why that shortcut works, and how it aligns with the lecture summary you provided.
1. The Shortcut: Why We Skipped
When we eliminate
However, the professor knew that the very next step was to eliminate
One of the foundational rules of probability is that all possible states of a single variable must sum to exactly 1. Therefore:
By calculating only the
In short, your instinct was completely correct: a full algorithmic execution would calculate
Step 3: Eliminating D
-
Action: Multiply the remaining factors involving
: and our new , then sum out . This creates a 1-variable factor . -
Math:
. -
Calculating for
: We use the prior probabilities for ( , meaning ). . . -
Calculating for
: Because the total probabilities must sum to 1, .
-
To understand why the intermediate factor
Variable Elimination is not an approximation; it is algebraically identical to calculating the full joint distribution and marginalizing variables out, just done in a smarter order.
Here is the step-by-step mathematical proof of why
The Mathematical Proof
If we want to find the true marginal probability
Now, let's look at how the Variable Elimination algorithm built
1. The creation of
2. The creation of
3. Combining the equations
If we substitute the mathematical definition of
Because of the distributive property, we can pull the summations to the outside and group the probabilities:
This final equation perfectly matches the definition of
The "No Evidence" Condition
This equivalency only happened because no evidence was observed in any of the ancestor nodes (
If we had observed evidence—for example, if we knew the student was highly intelligent (
-
We would not sum over
. We would restrict the table to only the values. -
As a result, the final factor
would no longer represent the general probability . -
Instead, it would represent the joint probability with the evidence:
.
Because there was no evidence acting as a constraint in the lecture's scenario,
Step 4: Final Elimination of G
-
Action: We are left with our target factor
and the intermediate factor . We sum out specifically for the condition . -
Math:
. -
. -
. -
.
-
The Conclusion
The calculation reveals that there is approximately a 50.6% chance of the student receiving a good recommendation letter.
As slide 20 summarizes, this specific elimination order was highly efficient. By eliminating the cheap leaf node